Metrics First Observability
Why Logs Should Support, Not Lead
In many engineering organizations, observability starts with logs. When something breaks, engineers open log search tools, filter by timestamps, scan error messages, and try to reconstruct what happened.
Logs are useful. But they should not be the primary way to understand whether a system is healthy.
In modern distributed systems, especially event-driven systems, observability should start with metrics. Metrics should be treated as first-class citizens. Logs should provide supplementary context to debug incidents, explain failures, and support root-cause analysis.
In simple terms:
Metrics should tell us that something is wrong. Logs should help us understand why.
The Problem with Log-First Operations
A log-first operating model does not scale well.
Logs are often noisy, expensive, and difficult to interpret. They are useful when an engineer already knows where to look, but they are not always effective at showing the overall health of a system.
In a distributed platform, one business transaction may pass through multiple services, queues, databases, APIs, and downstream systems. Searching logs across all those components during an incident is slow and reactive.
A log-first system often tells the story only after the damage is done.
Metric-first observability changes that model. Instead of waiting for someone to search through logs, the system continuously exposes its health through meaningful signals.
What Metric-First Observability Means
Metric-first observability means every critical system, service, and workflow is designed to emit meaningful metrics from the beginning.
These metrics should cover multiple dimensions:
- Business metrics — payments processed, payments failed, payments delayed, payments pending approval
- Workflow metrics — stuck states, retry counts, SLA breaches, lifecycle transition delays
- Platform metrics — Kafka lag, consumer errors, API latency, database latency
- Reliability metrics — availability, error rate, saturation, recovery time
The goal is not just to know whether servers are running. The goal is to know whether the business process is working as expected.
The best observability systems do not only tell us whether the platform is running. They tell us whether the business process is meeting its promise.
Why This Matters More in Event-Driven Systems
Metric-first observability becomes even more important in event-driven distributed systems.
In a synchronous system, failure is often visible immediately. A request fails, an API returns an error, and the caller knows something went wrong.
But in an event-driven system, everything operates asynchronously. A producer may successfully publish an event, but that does not mean the business workflow has completed. A consumer may be delayed. A message may be retried. A downstream system may reject the event. A payment may get stuck in an intermediate state.
In asynchronous systems, success at one step does not guarantee success of the workflow.
That is why metrics are critical. Metrics connect the dots across producers, topics, consumers, databases, and downstream systems.
For example, an event-driven platform should expose metrics such as:
- Events published per minute
- Events consumed per minute
- Consumer lag by topic and consumer group
- Event processing latency
- Retry count
- Dead-letter queue count
- Failed event count by reason
- Workflow completion time
- Business SLA breach count
In an event-driven architecture, the absence of an error does not mean the presence of success. Only metrics can prove that the workflow is moving forward.
Metrics, Traces, and Logs
Metric-first does not mean logs are unimportant. It means logs should play the right role.
A useful mental model is:
Metrics are the dashboard. Traces are the map. Logs are the evidence.
Metrics show the health of the system. Traces show the path of a request or event. Logs explain the details.
When an alert fires, the engineer should first understand the impact through metrics and dashboards. Then traces and logs can help explain the root cause.
Business SLO-Driven Metrics
Metric-first observability should also support business SLOs.
For example, in a payment platform, it is not enough to know that Kafka is healthy or that APIs are responding. The real question is:
Are payments moving through the business workflow within the expected time?
For an STP payment flow, we may define a business SLO like this:
99.5% of eligible STP payments should be released within one minute.
That SLO can be translated into alertable metrics:
- Total STP payments processed
- STP payments are released within one minute
- STP payments are taking more than one minute
- Percentage of delayed STP payments
- Delayed payments by client, currency, region, rail, or payment type
An alert rule could be:
If more than 0.5% of STP payments take longer than one minute to release within a defined rolling window, alert the rota.
This is powerful because the alert is based on business degradation, not just technical failure.
Metric-First Observability for Change Data Capture
Change Data Capture is another strong example.
In a CDC pipeline, data moves asynchronously from a source system to a target system. The source write may succeed, the CDC connector may capture the change, the event may be published, and the target database may eventually apply it.
Each step can fail or lag independently.
That is why CDC observability should not depend only on logs. Logs can explain why a specific record failed, but metrics should tell us whether the pipeline is healthy.
Important CDC metrics include:
- Source table row count
- Target table row count
- Source-to-target row-count mismatch
- CDC lag
- Events captured per minute
- Events applied per minute
- Failed apply count
- Retry count
- Dead-letter count
- Last successful sync timestamp
A simple but powerful control is comparing the source and target row counts. If the source table has 1,000,000 rows and the target table has 999,500 rows, the system should not wait for an engineer to discover that manually.
A metric should capture the mismatch, and an alert should notify the rota.
In CDC pipelines, correctness is not just about whether events are moving. It is about whether the target system faithfully represents the source system.
Operating Model for Metric-First Observability
Metric-first observability also requires a clear operating model.
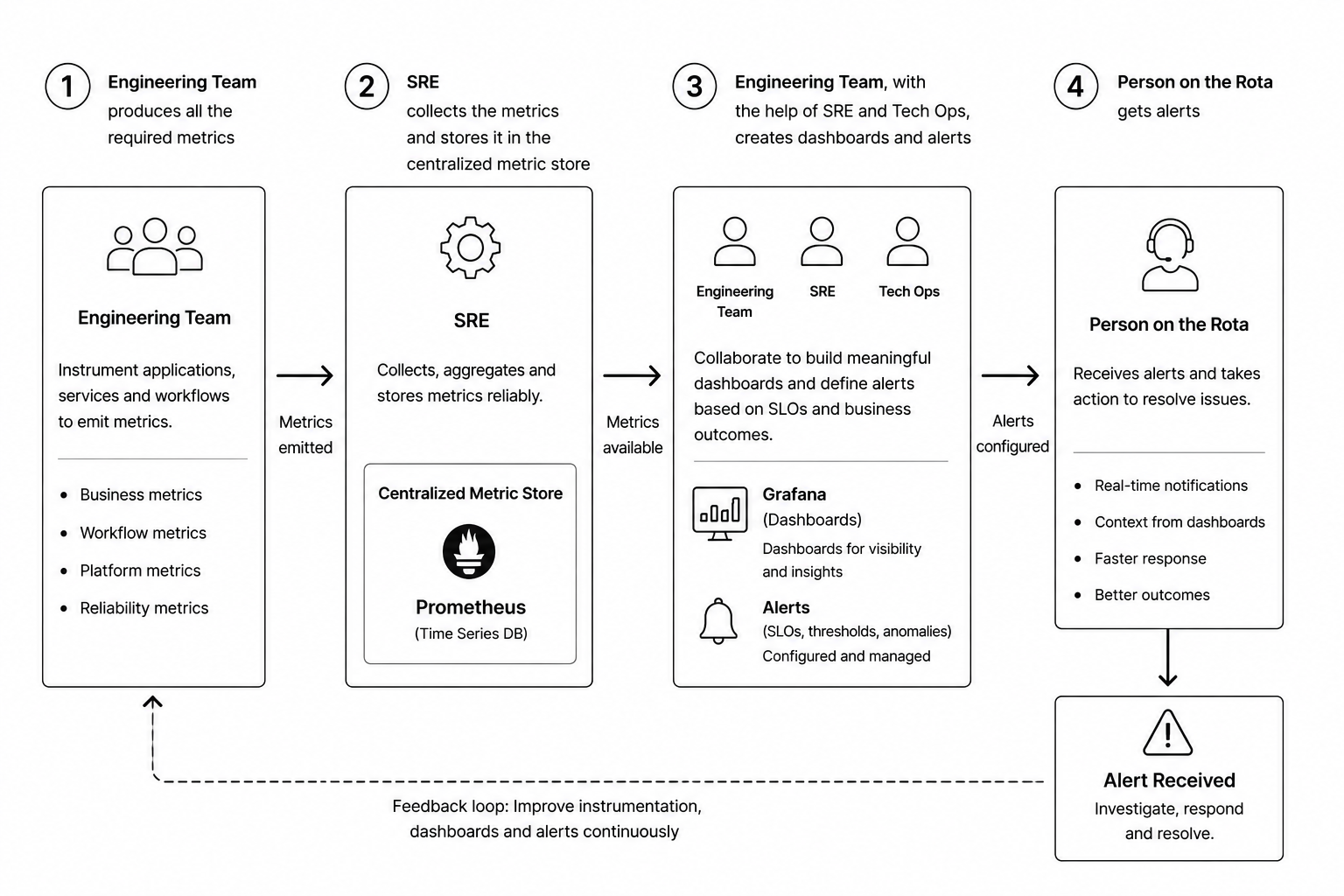
The engineering team is responsible for producing the required metrics. Metrics should be part of the application design, not an afterthought.
SRE is responsible for collecting, aggregating, and storing those metrics in a centralized metric store such as Prometheus or an equivalent platform.
Engineering, SRE, and Tech Ops should collaborate to create dashboards and alerts. These dashboards should represent both technical health and business health.
Finally, the person on the rota receives alerts when business or platform SLOs are breached.
The flow looks like this:
- Engineering instruments applications, services, and workflows.
- SRE collects and stores metrics centrally.
- Engineering, SRE, and Tech Ops create dashboards and alerts.
- The person on rota receives alerts and responds.
- Learnings from incidents improve future metrics, dashboards, and alerts.
This creates a continuous feedback loop.
Conclusion
Metric-first observability changes how teams operate distributed systems.
Instead of searching logs after something breaks, teams define meaningful metrics upfront. These metrics continuously expose the health of business workflows, event pipelines, CDC processes, and platform components.
Logs still matter. They help explain incidents and support debugging. But they should not be the starting point.
In modern event-driven systems, observability should begin with metrics.
The log should complete the story, not start it.